class: center, middle # DO NOT CLONE THE DATABASE --- # Introduction 1/2 It is generally agreed that cloning the database downstream (that is, from development toward production) is a bad idea, if only because by doing so all production content is lost; most developers use Features, Context, some variation on a site deployment module, or a rudimentary written procedure to move new configuration downstream. However, in a dev-stage-production workflow, the database is often still periodically cloned back upstream: 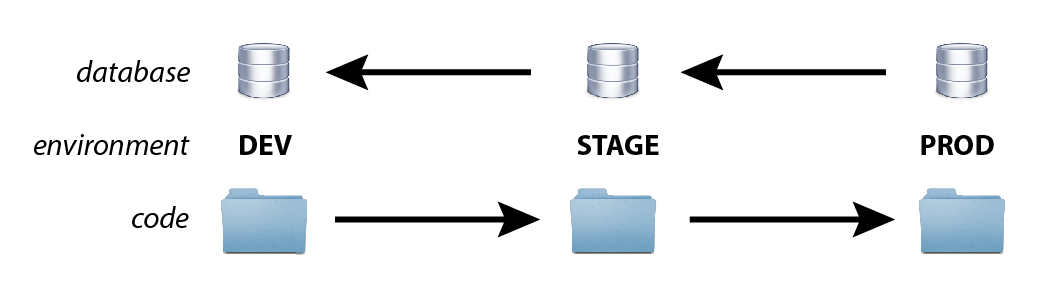 --- # Introduction 2/2 In such an approach, anything not in Features or a site deployment module exists solely in the database. For example: any content, your default theme, and other information (such as variables not exported with Strongarm or block placement information not exported with Context) are defined only in your database and not in code. Therefore, to create a realistic development environment, it is tempting to clone your database. I'll explain why I think database cloning is the wrong approach, and then look at other ways to achieve the same goals. Finally, I'll look at some situations where cloning the database is a good idea. --- # WHY IS CLONING THE DATABASE THE WRONG APPROACH? Cloning the database is wrong for the following reasons: * The database is not under version control. * The database is not a known-good starting point. * Database cloning makes automated testing harder. * Database cloning makes continuous integration harder. * What if there is more than one "production" site? * Your production database may be very large. * Your production database may contain sensitive data. * Fixes to a cloned database will "work on my machine", but not elsewhere. --- # THE DATABASE IS NOT UNDER VERSION CONTROL The database contains all configuration, content types, variables, views, and content; and none of this is under version control. A good development practice is to put everything except content into code, and into version control, via Features, Context, Strongarm, and a site deployment module. These are code and can be kept under version control. --- # THE DATABASE IS NOT A KNOWN-GOOD STARTING POINT One important aspect of writing modern software is the importance of automated testing, and the importance of knowing that our test will always yield the same result. This is the concept of a known good starting point, discussed in the book Continuous Delivery. The production database changes continually, for example when new comments or content are added. If your tests, either manual or automated, depend on a cloned production database, there is always a chance that different versions of the database will be yield different test results. --- # DATABASE CLONING MAKES AUTOMATED TESTING HARDER Because of the importance of having a known-good starting point, automated tests which require the database always work in the following manner: * Build a brand-new temporary (throw-away) database from scratch. * Perform a plain installation. * Create the required content and set the required configuration. * Perform the test. * Discard the throw-away database. --- # DATABASE CLONING MAKES AUTOMATED TESTING HARDER For example, let's say you have a block appear when there are more than 20 registered users on your site. The only way to accurately test this is to have your test control the number of users, and test the presence or absence of your block. If the only way to deploy a new environment with your site is to clone the database, the test has no real way of creating the conditions (active theme, block placement, active modules) to run this test. However, if you are using Features and a site deployment module, all your tests needs to do for the above example is to: 1. Enable your site deployment module. 2. Make sure the special block does not appear. 3. Create the 20 users. 4. Make sure the block does appear. --- # DATABASE CLONING MAKES CONTINUOUS INTEGRATION HARDER Continuous integration (CI) and continuous deployment are quite popular these days, with good reason, because without CI, automated testing is not that useful (because developers tend to ignore tests). Basically, CI runs a script on every push to version control. So: every time there is a change to the code base, the tests can be run and either pass or fail. I have seen many shops experiment with continuous integration, and in many cases the Drupal site is recreated by cloning the production database. Therefore, the CI server's test site is always in an unknown, unversioned state. So when a test fails, it is impossible to say whether a change to the database caused the fail, or a change to the code did. In my experience this causes frustration and confusion, and eventually will cause your CI server to be worthless, and hence abandoned. --- # WHAT IF THERE IS MORE THAN ONE "PRODUCTION" SITE? When we are cloning the production site's database, what do we mean exactly? Take the following example: we are developing a code base for a university with dozens of faculties. Each faculty uses the same code base but a different theme, and some slightly different settings. It doesn't make sense for new developers to clone one production database rather than another for development, so often a random choice is made, leading to uncertainty. Consider your codebase to be a software product which can be deployed on any number of sites, just as any software. Would it make sense for developers of a word processor to clone the computer of one of their clients during routine development? --- # YOUR PRODUCTION DATABASE MAY BE VERY LARGE Beyond the logical considerations, cloning production databases can be unwieldy, requiring one to remove cache tables, finding a mechanism to either copy all files and images, ignore them, or use placeholder files and images (that does not feel right, no?). Still, you can quickly find yourself with very large databases. --- # YOUR PRODUCTION DATABASE MAY CONTAIN SENSITIVE DATA Once your production site actually starts being used, you end up with much sensitive data there: email addresses, hashed passwords, order history, addresses, or worse. Consider the consequences if you dump this database on a developer's laptop (which will eventually be stolen or lost). --- # FIXES TO A CLONED DATABASE WILL "WORK ON MY MACHINE", BUT NOT ELSEWHERE So you've cloned a database on your laptop, and you changed some configuration on administration pages, and now the problem seems fixed, you've made a demo for your team and your client. The next part is messy though: a list of admin screens to click through on the production site to reproduce the fix (ugh!), or, as I've already seen, cloning the development database downstream (double-ugh!). Both methods are error-prone and do not record the fix in version control, so a month from now you'll forget how it was done. In fact, you will find yourself in a sysyphian effort of repeatedly fixing the same problem over and over, and explaining to your clients and your team, with the help of out-of-date wiki pages, email exchanges and undecipherable comments on issue queues, that you are not an incompetent oaf. --- # WHAT ARE THE ALTERNATIVES TO DATABASE CLONING? We generally clone the database to have a realistic development environment. Among other things, during development, we need to have: * The same configuration and features. * Realistic content. * Some exact problem-causing content. This is possible without cloning the database. Here are some tips and techniques. --- # GETTING THE SAME CONFIGURATION AND FEATURES AS PRODUCTION In an ideal world any Drupal site should be deployable without cloning the database, by getting the code from git and enabling the site deployment module. You are most likely, however, to inherit a site which is a mess: no site deployment module, no tests, with Features, if they exist at all, likely to be overridden on the production site. On some projects you'd be lucky to even have a git repo. One might think that for such sites, which we'll call legacy sites for the purpose of this article, cloning the production database is the only viable option. Unfortunately, that is true, but it should only be a temporary solution, to give you time to extract the important configuration into code, and to create a site deployment module. --- # GETTING THE SAME CONFIGURATION AND FEATURES AS PRODUCTION Let's say, for example, I get a work request to "fix a little bug on a site which is almost ready". The first thing I do is to clone the entire site to my laptop, with the database and all, and determine which configurations, features, and variables are affected by the bug. Let's say the site in question has 20 content types, 20 views, 50 enabled modules, three languages and a custom theme. But the bug in question only affects 2 content types, one view, 3 modules and does not require the custom theme or i18n. I would start by generating a feature (if one does not exist) with the required views and content types, and a site deployment module with the feature as a dependency and a basic automated test. Now I can use test-driven development to fix my bug, push everything back to version control and to my continuous integration server, and deploy to production using drush. Thus, every time an issue is being worked on, a site gradually moves from being a legacy site to a modern, tested site with continuous integration (don't do it all at once as you will get discouraged). --- # REALISTIC CONTENT For developers, Devel's devel_generate module is great for generating lorem ipsum content with dummy images, so even if you don't clone your database, you can still get, say, 50 (or 1000) blog posts with 5 (or 50) comments each. During automated testing, several DrupalWebTestCase API functions allow you to create as much dummy content as you want, being as specific as you want. --- # WHEN IS IT OK TO CLONE THE DATABASE? "Don't clone the database" is a good rule of thumb, but in some cases cloning the database is good idea, for example in the following cases: * For backups and restores. * For hard-to-debug "production-only" problems. * As a temporary measure to update a legacy site. * For proproduction environments. --- # FOR BACKUPS AND RESTORES Code is not everything. The database contains your content, so you need to have a strategy to clone your database somewhere nightly, test it often, and make sure you can restore it. This is mot easily done by cloning the database. --- # FOR HARD-TO-DEBUG "PRODUCTION-ONLY" PROBLEMS Once in a while, you will have a problem which only manifests itself on a production site. Reproducing this type of problem systematically can be best achieved by cloning your production database to figure out what the problem is (never work directly on production, of course). --- # AS A TEMPORARY MEASURE TO UPDATE A LEGACY SITE As mentioned in "Getting the same configuration and features as production", above, most projects are a complete mess once you get your hands on them. We'll call these legacy sites. The only way to move important configuration information into code is often to clone these sites temporarily until you have working Features and a site deployment module. --- # FOR PROPRODUCTION ENVIRONMENTS For some critical projects, you might decide to continually deploy, but not directly to production. In such circumstances, you might have your Jenkins projects continually deploy to a preproduction site (cloned from production before each deployment), to give the team, and the client, a few hours or a day to walk through the changes before approving them for deployment to production. --- # CONCLUSION Since being interested in dev-stage-prod, deployment and testing, I have often come across colleagues who systematically cloned the database, and have always felt uneasy about it, and in writing this post I have set out to explain why. The post turned out a lot longer than I thought, and the main take-away is that we should all consider our sites as software products, not single-use sites. As software products, we need standardized deployment methods, both initial and incremental, via a site deployment module. As software products, we also need to implement modern testing and continuous integration techniques. As software products, we need to be able to deploy anywhere, with no environment dependant on any other. --- # CONCLUSION Such a focus on reproducibility will hopefully pave the way to more dependable tests, a better understanding of what is content and what is configuration, and faster, more efficient and more consistent development. --- # Reference http://dcycleproject.org/blog/48/do-not-clone-database http://www.swisscom.ch/its/dam/documents/whitepapers/wp_test-data-management_conference-journal_de.pdf